| A disaster recovery plan is a documented set of procedures and resources that enables a business to restore its IT systems, data, and operations after an unplanned event such as a cyber attack, hardware failure, natural disaster, or major outage. |
What would happen to your business if every server, application, and file became unavailable for three days? For most NZ businesses, the answer is uncomfortable, and the longer the outage runs, the bigger the bill in lost revenue, missed deadlines, and reputational damage.
Industry studies consistently put the cost of unplanned IT downtime in the thousands of dollars per hour for a typical SME, and that is before you account for the longer-term hit to customer trust. The businesses that come through an incident intact almost always have one thing in common: they prepared for it in advance.
A disaster recovery plan is what separates a brief interruption from an existential crisis. It is the documented blueprint that tells your team exactly what to do, who does it, and how quickly each system should be back online.
This guide walks through what your plan should contain, how to build one that holds up under pressure, and how to test it so you do not discover the gaps in the middle of a real incident.
What Is a Disaster Recovery Plan?
A disaster recovery plan is a written document that defines how an organisation will respond to and recover from events that disrupt its IT systems and data. It covers the technology, the people, and the processes needed to bring critical operations back online within a defined timeframe.
The plan is not a document for cyber attacks alone. A well-built plan covers any scenario that takes systems offline, including fire, flood, power failure, ransomware, hardware faults, supplier outages, and human error.
It sits inside a broader resilience strategy and works alongside a business continuity plan and your insurance arrangements, but it focuses specifically on the technology side: data, applications, networks, and the systems that run the business day to day.
How Does a Disaster Recovery Plan Differ From Business Continuity?
A disaster recovery plan focuses on the technology. A business continuity plan focuses on the whole organisation. The disaster recovery plan asks how do we get our systems back, while business continuity asks how do we keep the business operating while those systems are down.
In practice the two work together. Your plan might commit to restoring the customer database within four hours, while the business continuity plan defines how the customer service team handles enquiries during that window using printed lists and manual processes.
Why Do NZ Businesses Need a Disaster Recovery Plan?
The threat landscape facing NZ businesses keeps expanding. Cyber attacks, ransomware, and supply chain failures sit alongside the more traditional risks of flood, earthquake, and power outage that the South Island knows well.
Without a disaster recovery plan, recovery becomes improvisation. Decisions get made under pressure, by people who may not have the authority, the access, or the technical knowledge to make them well. A documented plan removes that guesswork and gives your team a clear sequence of actions to follow.
Insurers, large clients, and regulators increasingly ask to see a current disaster recovery plan as part of due diligence. For many NZ businesses, having one in place is no longer optional.
What Should a Disaster Recovery Plan Include?
A solid disaster recovery plan includes recovery objectives, a system inventory, defined roles, backup strategy, communication protocols, and tested procedures for each critical system. Skipping any of these leaves a gap that will appear at the worst possible moment.
Most plans also include vendor and supplier contact details, alternate work locations, and a clear chain of authority for declaring an incident and approving recovery actions. The aim is that someone reading the plan for the first time, under pressure, can still execute it.
Communication is often the part teams overlook. Staff need to know what to do and where to go. Customers need to know what to expect. Suppliers, insurers, and in some cases regulators need to be notified within set timeframes. Pre-written holding statements and a clear escalation tree remove hours of guesswork during the first response.

What Are RTO and RPO?
Recovery Time Objective (RTO) is the maximum acceptable downtime for a system. Recovery Point Objective (RPO) is the maximum amount of data the business can afford to lose, measured in time.
If your accounting system has an RTO of four hours, it must be operational within four hours of an incident. If the same system has an RPO of one hour, your backups need to capture data at least once every hour so you never lose more than 60 minutes of work.
Every system in the plan should have its own RTO and RPO. Email might need an RTO of one hour. The historical document archive might tolerate 48 hours. Setting these targets in advance makes investment decisions, data backup strategy, and infrastructure choices far more rational.
What Roles and Responsibilities Should Be Defined?
The plan must name specific people and specific roles, not job titles alone. Someone has to declare the incident, someone has to authorise spending, someone has to communicate with staff and customers, and someone has to lead the technical recovery.
Each role needs a primary and a backup. People take leave, get sick, or are themselves caught up in the disaster. If only one person knows the recovery procedures, the plan has a single point of failure built in from day one.
How Do You Build a Disaster Recovery Plan?
Building a disaster recovery plan starts with understanding what you are protecting. You cannot recover what you have not inventoried, and you cannot prioritise recovery without knowing which systems generate revenue, hold sensitive data, or sit at the centre of daily operations.
The process typically runs in four stages: risk and impact assessment, system prioritisation, recovery strategy design, and documentation. Skipping straight to writing the plan without doing the assessment work first produces a document that looks complete but fails the first real test.
How Do You Assess Risks and Business Impact?
A risk and impact assessment identifies what could go wrong, how likely each scenario is, and what the business consequences would be. The combination of likelihood and impact tells you where to focus.
A flood in the server room may be rare but catastrophic. A ransomware infection on a workstation may be common but contained. A plan that treats both the same way wastes effort. Use the assessment to direct investment toward the risks that matter most and to set realistic recovery targets for each scenario.
How Do You Prioritise Systems for Recovery?
Not every system is mission-critical. Group your systems into tiers based on how quickly the business needs them back. Tier 1 might be revenue-generating systems such as your point of sale, ordering platform, or production line. Tier 2 might be supporting systems such as email and accounting. Tier 3 covers everything the business can survive without for several days.
This tiering exercise produces the RTO and RPO targets that drive your backup design, your infrastructure spend, and your recovery sequence. Trying to recover everything at once stretches resources thin and delays the systems that matter most.
How Do You Design the Recovery Strategy?
The recovery strategy turns your targets into infrastructure. A system with a one-hour RTO needs near-instant failover, often through cloud replication or a hot standby site. A system with a 48-hour RTO can rely on standard backups restored to replacement hardware.
The strategy should also address dependencies. Restoring a customer-facing application does no good if the database it relies on is still offline, or if the authentication service has not been brought back first. Map the dependencies before you commit to recovery sequences.
Cost rises sharply as recovery targets tighten, so the strategy needs to be honest about trade-offs. Near-zero downtime is achievable but expensive, and not every system justifies that investment. The exercise is matching the cost of recovery infrastructure to the cost of the downtime it prevents, system by system.
How Do You Test a Disaster Recovery Plan?
A disaster recovery plan must be tested regularly to confirm that it actually works. An untested plan is a hypothesis, not a strategy, and the gap between what the document says and what happens in practice is almost always larger than expected.
Testing reveals issues that paper review never catches: out-of-date credentials, missing dependencies, backup files that fail to restore, contact lists pointing to people who left the business, and procedures that assume access to systems which are themselves offline.
What Testing Methods Work Best?
Three test types together cover most needs. A tabletop exercise walks the team through a scenario verbally, testing decisions and communication without touching live systems. A partial test recovers a single system or service to an isolated environment to confirm the technical procedures work. A full test simulates a complete disaster and brings services back end to end.
Run tabletop exercises quarterly, partial tests at least twice a year, and a full test annually if the business can support it. Each test should produce a written report with findings, owners, and corrective actions tracked through to completion.
How Often Should the Plan Be Updated?
A disaster recovery plan should be reviewed at least every six months and updated whenever there is a significant change. New systems, new staff in key roles, changed suppliers, or upgraded infrastructure all trigger a review.
Test outcomes also drive updates. If a recovery exercise reveals that the procedure takes twice as long as the plan claims, fix the document and adjust the RTO, or invest in faster recovery infrastructure. A plan that is never revised quickly becomes fiction.
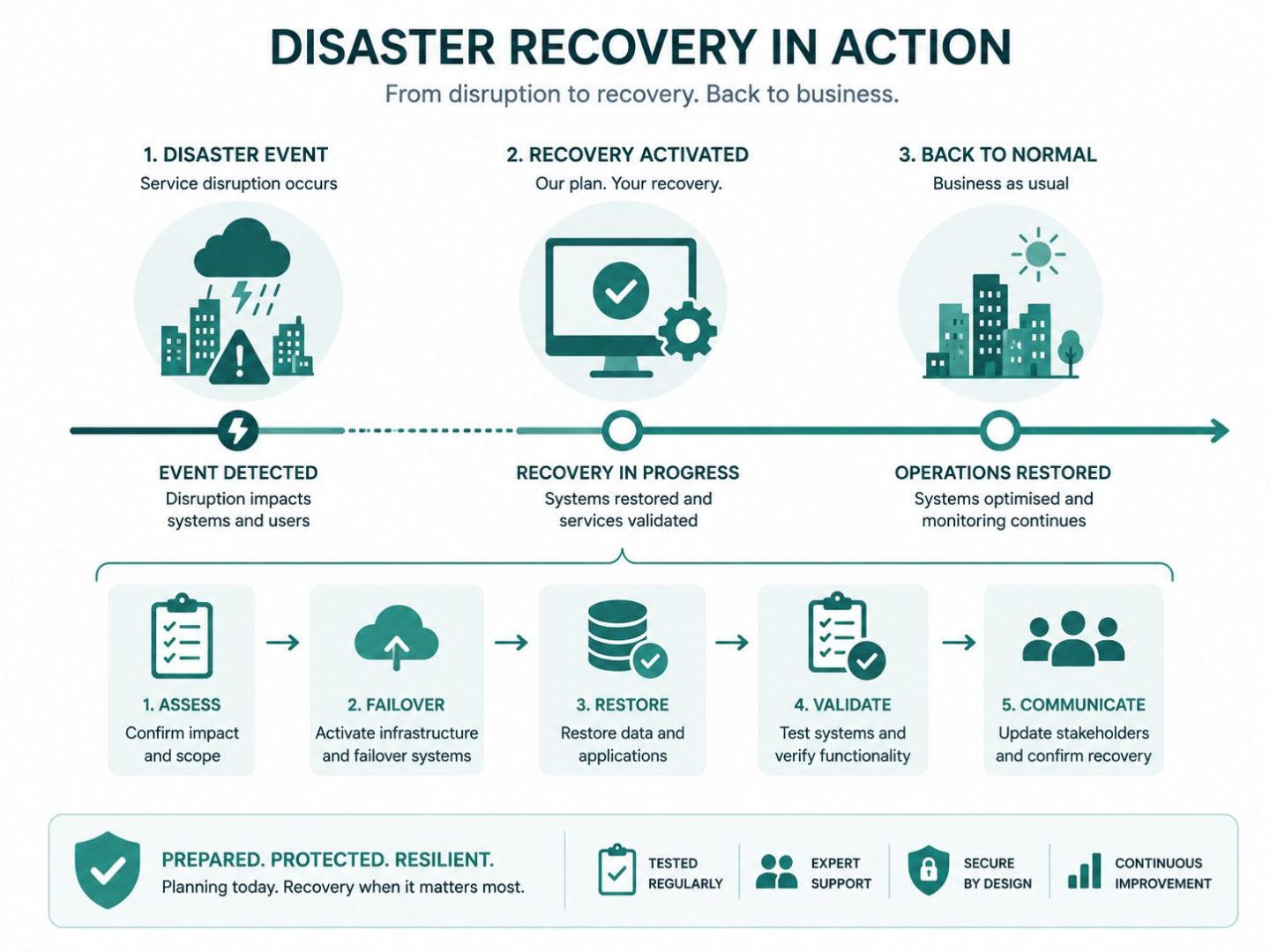
What Common Mistakes Undermine a Disaster Recovery Plan?
The most common mistake is treating the disaster recovery plan as a one-off compliance document. A plan written and shelved becomes inaccurate within months as systems, suppliers, and staff change. The second most common mistake is failing to test, which means the first time the plan runs end to end is during a real incident.
Other recurring problems include backups that are never verified, recovery procedures that depend on systems which are themselves down, single points of failure in the response team, and contact lists that have not been refreshed in years.
Two further pitfalls catch businesses out. The first is storing the plan only in digital form on the systems the plan is meant to recover, so when those systems go down the plan goes with them. The second is overly optimistic recovery targets set without the supporting infrastructure to meet them, which leaves the business committed on paper to outcomes it cannot actually deliver.
How Do Backups Fit Into the Plan?
Backups are the foundation of any recovery effort, but a backup alone is not a recovery strategy. The plan needs to define what is backed up, how often, where backups are stored, and how long restoration actually takes in practice.
The widely used 3-2-1 rule still holds: three copies of the data, on two different media types, with one copy offsite. A modern cloud backup approach typically delivers the offsite copy automatically and shortens restore times compared with tape or external drives.
How Does Cyber Insurance Connect to the Plan?
Cyber insurance and a disaster recovery plan reinforce each other. Insurers increasingly require a documented and tested plan before issuing or renewing cover, and a clear plan reduces the cost of an incident, which protects your premiums over time. Read more on how cyber insurance interacts with operational resilience to align the two properly.
Strengthen Your Disaster Recovery Plan With Exodesk
Building, testing, and maintaining a disaster recovery plan takes time, technical depth, and an honest view of the risks facing your business. Exodesk supports Christchurch, Dunedin, and South Island businesses with managed IT services that include disaster recovery planning, backup architecture, and recovery testing as part of an ongoing programme.
Contact us today to discuss how we can help your business or connect with us on LinkedIn to stay updated with more insights.
Frequently Asked Questions
What is a disaster recovery plan?
A disaster recovery plan is a documented set of procedures that defines how a business will restore its IT systems, data, and operations after an unplanned disruption. It covers recovery targets, responsibilities, communication, and technical steps. Every system covered by the plan should have a clear recovery time and data loss tolerance.
What is the difference between disaster recovery and business continuity?
Disaster recovery focuses on restoring IT systems and data after an incident. Business continuity focuses on keeping the whole organisation operating, including non-technical functions, while recovery is underway. The two plans work together: business continuity uses workarounds while recovery brings the technology back online.
What are RTO and RPO in a disaster recovery plan?
Recovery Time Objective (RTO) is the maximum acceptable time a system can be offline. Recovery Point Objective (RPO) is the maximum amount of data the business can lose, measured in time. Together they define how fast you must recover and how recent your last backup must be.
How often should a disaster recovery plan be tested?
A disaster recovery plan should be tested at least annually with a full or partial recovery exercise, and supported by quarterly tabletop reviews. Testing more often is preferable for high-risk industries or businesses with rapidly changing IT environments. Every test should produce a written report with findings and corrective actions.
How long does it take to build a disaster recovery plan?
Building a useful plan typically takes between four and twelve weeks, depending on the size of the business and the complexity of the IT environment. The work includes risk assessment, system inventory, recovery target setting, procedure documentation, and an initial test. Plans built in less time often skip the analysis phase and fail when tested.
Who is responsible for the disaster recovery plan?
Overall ownership usually sits with senior management or a designated business continuity manager, with day-to-day responsibility delegated to the IT team or managed IT provider. Specific roles within the plan should be assigned to named individuals with primary and backup cover. Without clear ownership, plans drift out of date quickly.
Does a small business really need a disaster recovery plan?
Yes. Small businesses are often more exposed to disruption than large ones because they have fewer resources to absorb downtime and fewer redundant systems. The plan does not need to be lengthy, but it does need to cover the critical systems, the recovery steps, and who does what.
What systems should be covered in a disaster recovery plan?
A disaster recovery plan should cover every system the business depends on to operate, including email, accounting, customer databases, file storage, line-of-business applications, websites, and phone systems. Each system gets a recovery priority, a target RTO and RPO, and a defined procedure. Lower-priority systems can be grouped together with longer recovery targets.
How does cloud computing change disaster recovery planning?
Cloud services shift some of the recovery burden to the provider but do not remove the need for a plan. Businesses still need to manage data backup, user access, configuration, and the interactions between cloud and on-premises systems. A modern plan covers cloud, hybrid, and any remaining on-premises infrastructure.
What is the first step in creating a disaster recovery plan?
The first step is a risk and business impact assessment to identify the threats facing the business and the consequences of each major system going offline. From that assessment you can set recovery priorities, define RTO and RPO targets, and design the technical strategy. Without this foundation, the rest of the plan is built on assumption rather than evidence.

